
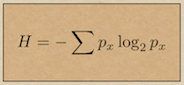
Clarifying the confusing language of Information
By Dr Keith FarnsworthYes, no doubt about it, the language surrounding information is a mess. There are too few words and those we have are used in too many ways to make oneself understood without ambiguity. In part this reflects underlying conceptual weakness - the concepts needed are difficult and often still forming. It also reflects the wide differences of traditions of thought that converge on this subject - philosophy and engineering are not often found together, but biology and cosmology are also in on this party.
Cut to the chase: here is a suggested set of definitions that organise and clarify, at least most of the concepts we need to specify in considering information and its many consequences. After the definitions, I provide some justification and explanation.
Definitions
Ensemble: any set of physical
entities arranged in time and space, e.g. molecules. The ensemble is
the basis for information to be embodied (consistent with Landauer’s
dictum: information is physical). Data: a particular configuration (arrangement) of an ensemble. This is termed a micro-state in physics, a sequence or simply data in computer science and bioinformatics. Data is not about anything, it is literally just a configuration: the word refers to an entity, not the properties of an entity.
Intropy: the number of ways an ensemble can be arranged. This is the capacity of the ensemble to hold data. It is a statistical property of the ensemble and the first word referring to quantitative properties of patterns, rather than the patterns themselves. (Note intropy is often referred to as information entropy, or just 'entropy', but that is too easily confused with thermodynamic entropy, so I deliberately chose a different, but related word).
Pattern: any configuration (data) embodied by an ensemble which has non-zero auto-mutual information at any trans-location distance (delay or shift referring to a sequence). Pattern therefore refers to an entity, not the properties of that entity. Non-zero auto-mutual information just means that there are larger-scale features in the data, to put it another way, a courser-grained version of the data will show consistent differences on a more 'regional' basis. It is the formation of patterns among atoms and molecules that gives rise to recognisable materials and objects; otherwise everything would be just 'grey soup'.
Autonomous information: the quantification of data or a pattern in terms of information properties, especially its maximally compressed size in bits (calculated by e.g. its Kolmogorov complexity). In this sense information is to pattern as mass is to matter. You will notice that I reserve the term 'information' for quantifying a property of an entity (in this case a pattern), not for the entity itself.
Relational information: the mutual information (in the sense of statistics) among data (especially if at least one of the data-ensembles is a pattern). This is a quantity and is what Shannon adherents refer to as ‘information’. Every data is a potential source for relational information, so has potential information, but not yet realised by partnering with another data. Relational information is strictly a relational phenomenon that cannot be attributed to any single data: it is a property of the ensemble of data. Since it is mutual information, it is a metric describing entities, not the entities themselves. In the classic Shannon description, Relational information quantifies the change of uncertainty about one data, when given the other (in this sense, the other 'informs' us about the former).
Effective information: The autonomous information (quantity) of any data with causative power over any data when it interacts with another data to form relational information (the resulting change* may be in the partner data, in itself, or any other data). Effective information describes the additional informational property of causation which may arise alongside the formation of relational information. Effective information can only be observed when data form relational information through interaction. A pattern may cause an effect in non-pattern data to form a pattern (e.g. the RNA-ribosome complex makes patterns from an unordered mix of amino acid substrates). A pattern may also cause a consistent effect in relation to a variety of partner patterns (e.g. it may be an enzyme that cleaves a range of proteins). Effective information is a context dependent quantification of the autonomous information in a data with causitive power, since its actions depend on what, if anything, it interacts with. Thus a data X may have autonomous information x and only in the context of interacting with another data Y, might this become effective information. Further, we might take away from x and still find the same caustive power of X over Y. The effective information of X will be the minimum x that produces the full effect.
*Note that in general change is not necessary: the effect may be to maintain stasis (i.e. to inhibit change). In this sense, a pattern may be effective on itself because it maintains its form (e.g. in a crystal, which is an ensemble created by electrical field patterns, the ensemble pattern is self-reinforcing with the effect of inhibiting dissolution).
Functional information: when the effect of effective information operates at a higher ontological level, then its effect can be called functional. Note this does not imply a purpose (as many attempts to define function have: see here). For example, a mutant gene has an effect once it is expressed and this effect can be described as a change in cell functioning (i.e. at a higher ontological level compared to gene expression): thus the gene (a pattern) is functional at the higher level of the cell. Interacting patterns can form complexes that have actions which can be attributed to the organisational level of the complex - this being a higher ontological level than that of the patterns composing it. Since the effect is manifest at a higher ontological level, it is 'emergent' at that level, so the interaction that produced it is a candidate for creating a transcendent complex (though probably not on its own). In this system of thought, function, emergence and causation are interlinked and functional information quantifies the contribution of component patterns to the behaviours which emerge from their interactions.
In turn the complex may interact with other complexes to result in actions at a higher level still. The hierarchical nesting of such relationships is the structure of life. We can quantify it through estimating the effective information which is found at the complex (i.e. system) level, through aggregating over its component parts.
Meaning: The term ascribed to functional information in which the function is essentially informational rather than physical. Cleaving a molecule is essentially a physical function, creating a new pattern is essentially an information function (though this is never entirely separate from the physical). For example, the action of a Turing machine (an information processor) when fed input ‘data’, producing output ‘data’ is functional and the function is the creation of patterns (the output), so we can say that the input has meaning for the Turing machine.
Many philosophers would quibble with this use of the word 'meaning', but we should not forget that this use is a narrow and technical application of the word, to meet a need that is not met by any other word.
Knowledge: is autonomous information (as stored pattern) embodied by a system which exists at a higher ontological level for which the autonomous information would be functional if it were to interact with some other pattern within the same system. Knowledge differs from functional information because it describes the entity of pattern, whereas functional information describes quantitative properties of the pattern. The obvious example is a gene which is embodied pattern within the cell and has potential function at the level of the cell: the gene is knowledge, it is quantified by its functional information. The patterns of ink on the pages of a book is not knowledge because it is not stored within the system for which it could be functional. Once read and remembered, it becomes knowledge. If however it is not potentially functional, then it becomes mere pattern stored by embodiment in (the brain) of the system (person). Whether or not it is potentially functional is, of course, a mute point. Note that knowledge is most frequently thought of as informational (implying that it is composed of meaningful patterns), but it is not necessarily so: the gene may for example be physically functional at the level of the cell and therefore be knowledge as it is autonomous information embodied by a system for which it has function. Knowledge is quantified by functional information, it is not itself information.
Wisdom: A system of knowledge components which collectively form a higher ontological level of informational structure with positive function for the system that embodies it. Note that wisdom is informational (data-based), but existing at an ontological level greater than that of knowledge: it is pieces of knowledge that form mutual relations with function at the higher (system) level. For example, a set of pieces of knowledge about the law, organised in such a way that they have informational function at a higher ontological level of information (understanding of the law) constitutes wisdom (which is positively functional for the person in possession of this system of knowledge (by embodiment in their brain). Wisdom is specifically defined by positive function (meaning that which contributed to an increase in the system’s (e.g. person’s) fitness). This is partly an acknowledgement of convention (wisdom that negatively affects a person is possible, but seems a contradiction) and partly because wisdom is most likely a large information structure, therefore requiring considerable effort (resources) to maintain it, so is likely to be lost by natural selection (general, not just in life) if it were overall negative in its effect on the system which carries it. We could say that the whole genome is wisdom for the cell, even though parts of it may be deleterious. The whole genome is composed of pieces of knowledge, these form a system (higher ontological level) of information interacting (through epigenetic relationships), the net result of which is positive for the fitness of the cell (else it would not persist). Wisdom can therefore be quantified (in principle) as functional information at the highest operating ontological level.
Quick Explanations
These definitions make a clear separation between what I am
calling autonomous information (which is the more or less
Aristotelean idea) and relational information (which captures what the
Shannon information theorists call information). It also distinguishes
between uses of the
label ‘information’ to mean ‘a thing’ from those which refer to
properties of the thing. Then we have intropy: the capacity for
potential information; autonomous information, which is autocorrelated
(pattern) embodied and has the property of potential information; two
or
more of which can give rise to relational information, which is the
mutual information among the data, or patterns). Effective information
is a
label for any pattern with causative power and functional information
is any effective information having causative power at a higher
ontological level. This is the basis of a hierarchy of upward
causation, by which complex systems (e.g. life) are
structured. This system includes meaning, knowledge and wisdom as
informational concepts which can be derived from more
elementary ones, with ultimately a physical basis. I believe this is
the first time that has been done.The starting inspiration was an idea of information as a single entity which aggregates in a series of organisational ‘scales’: a hierarchical nesting, analogous to that of matter where particals => atoms =>molecules=>supramolecular structures=>substances and so on. A very rough (hand waving) sketch of this already exists, and has done from ancient times. It goes something like this: data=>information=>knowledge=>truth=>wisdom (there can be debate about the order of some of these). The first insight here is that there is something fundamental, like a particle of ‘information’, which when organised into groups, creates something from which new properties seem to emerge. These new properties are what we use to identify and describe the resulting aggregation. Not only that, but there are several nested levels of aggregation, so that we have several sets of properties to describe, each relating to the next higher level of aggregation of aggregations. These properties are therefore hypothesised to be transcendent complexes. It seems to also be important to make a clear distinction between words that describe entities based in physical reality and quantities describing their properties. Following the tradition of Shannon information theory, I keep the word 'information' for the quantities and other words have to do the work of describing the entities which may have information properties.
A Longer Account
Introduction
A variety of different notions all labelled ‘information’ are used in science and it is very important to recognise their difference, but because they all share the same label, this has become very difficult. The result at the moment is confusion and ‘talking at crossed-purposes’, even at meetings of experts in the field. The history of science shows that sometimes the creation of a systematic structure of definitions leads to a new flourishing of discovery and understanding (we can think of the periodic table of elements, or the taxonomic classification of organisms). Here we attempt to systematically define notions of information, specifically for use in science. This is not the first attempt and we commend previous efforts such as that of Luciano Floridi (see here). By systematic, we specifically mean defining the different notions and their relation to one another in terms of a broad structure, or framework, that makes sense of their differences and similarities. This is what the periodic table and taxonomic classifications of organisms do.
Entropy and Intropy
The raw material for information is ‘entropy’, more precisely meaning informational entropy (sometimes (and here) termed intropy). It is quantified as the logarithm of the possibility number: the number of ways a system can be arranged. What it describes is the total number of differences within a physical system. These differences can be among different kinds of components making up the system, but also include the different spatial locations of those components. Put simply, the more ways a set of things can be arranged, the more we can have to say about the set and the more information it could (if put to the task) convey or store (though Shannon adherents will not like that language, so let's just say the more questions one could usefully ask). We could have, say, a bag of coloured balls and ask how many different sequences we could get from taking them out one by one. This is a popular idea in bioinformatics, where we can calculate the intropy of the sequence of bases (nucleic-acids) in, e.g. a DNA molecule. A string of five can, hypothetically, be made in 45 (i.e. 1024) ways, which means it can store or convey at most 10 bits of information (see here). Each difference among the ensemble is a unit of data and intropy is counted in data units, even though it does not directly quantify data. Intropy quantifies the number of ways the data can be arranged. Whislt intropy can refer to data in abstract, It is important to remember that it often applies to real entities, where it measures the number of ways something physical can be arranged: data embodied by physical objects located in time and space (be it a cloud of molecules in a gas, the position of atoms in a protein molecule, or the pattern of electron states in your computer’s memory chips, etc.). Intropy is most certainly not to be confused with entropy.
Scientists have adopted the position that intropy is not itself information. Along with most other people, they regard information as being, by definition, about something. The intropy of a system is not its information content, rather it is the information capacity: how much information it could potentially store or convey. But what does "about something" really mean? The concept implies that information cannot be an intrinsic commodity or property, but instead must describe the way one entity relates to another: specifically, how much a knowledge of one gives us a knowledge of the other. This defines information as a relational property and one that can be quantified. The question: how much does A relate to B, is answered by finding the correlation between A and B. More generally and technically, this required the calculation of the mutual information between A and B. It is what A can tell you about B and vice versa.
However, there is an alternative tradition of thought, dating back to Aristotle, that regards information as being something in and of itself. Instead of being a relational property among patterns in matter, it is the pattern itself. This concept is one of information instantiated by its embodiment in the form of a structure (a shape, a molecule, or a machine part). It is what makes that thing what it is. Information is understood to only exist in a physical form as a pattern, for example in the stripes of magnetisation on a hard disc or the shape of a protein molecule. But in this view, information is raised from being an attribute of arrangements in matter, to the essence of existence of those arrangements and it is intrinsic, not a relationship depending on at least two other entities.
Autonomous and Mutual Information
Information about something only exists if it shares ‘mutual information’ with that thing. What then, of information that instantiates the body which embodies it? This information could be said to be about itself, or rather, about the body which embodies it. I call this autonomous information. Whilst logically self-consistent, this statement seems almost tautological, but can be made use of once we think what it means to be a body (in the physical sense). A body is a coherent organisation of matter; the alternative being a random arrangement of particles. Random implies that there is no internal correlation (i.e. autocorrelation) so that no part of the pattern of arrangement shares mutual information with any other part. Thus a body, is an arrangement in which there is some mutual information in the configuration of at least some of its parts. By this, we can apply the same mathematical test to inherent information as we can to relational information and to that extent reconcile the two traditions of thought. Indeed we can start with the proposition that information is always relational. Then what is it a relation between? The answer must be two (or more) patterns, which themselves are information by virtue of the fact that they relate to one another. This provides a defining restriction: a set of differences (data) can only be information in relation to another. But that other may be another part of a body which is instantiated by the information patterns that relate to one another so as to form the body. This can only be the case if patterns contain some mutual information, so autocorrelation is the clear sign that such a phenomenon is present. The alternative is that the pattern of an assembly of particles is random and therefore not information. Mathematically, what distinguishes the truly random is that it does not correlate with any translocated copy of itself, which has the effect that knowledge of even all but one piece of it is no guide to what the remaining piece might be.
An exception that proves the rule
We can easily conceive of a pattern that has the statistical properties of randomness and yet may also be information. Understanding this is very important for the most popular uses of computers these days: the conveyance of entertainment over restricted communications channels, but it has been a concern since at least the second world war when important messages had to be sent in very restricted conditions. Most readers will be familiar with predictive text (on the mobile (cell) phone or word-processor. It only works because, in valid writing (e.g. English or Spanish), some groups of letters only ever occur in combination with another group, so the appearance of these letters predicts the others, which thereby become redundant. We could then leave out the predictable letters in a transmission and leave an algorithm to sort that out on the receiving end. I am sure you can tell what this says: th qk brn fox jmpd ovr th lzy dog. That is a moderately compressed message. If we were to compress to the limit, then no letter in the remaining sequence would be at all predictable from any other there. This maximally compressed message would still be readable, with some processing, but it would have no autocorrelation and would therefore be mathematically indistinguishable form a random sequence of letters. That is a general rule: a maximally compressed and therefore maximally efficient code has no autocorrelation and has the properties of a random signal. Why then is this random string of characters still information? The answer is that in (at least) one special context it may have some non-random effect, even though it is statistically a random sequence. This can only happen because it correlates with another pattern in some other place and/or time, which we may call the receiver. The act of receiving data is ‘reading’ it and the essence of reading data is correlating with it, so that it becomes information.
Given this, we now have that a pattern has information if either it correlates (to some extent) with another pattern or with itself. Since by definition a pattern does correlate with itself, it always has autonomous information.
The mutual information idea rather nicely matches the concept of a transmitter and a receiver of information communicating over an information channel, which is the founding concept in Shannon’s information theory. That theory is taken as the basis for understanding information by many in science and engineering. But ‘information theory’ is at best a confusing term for Shannon’s work, since it deals only with the communication of data and data in general includes intropy, since data is any set of detectible differences. Despite that, the application of Shannon’s ideas has yielded great insight into molecular biology (pioneered by Tom Schneider and Chris Adami among others).
We may ask if information stored on an old floppy disk in the attic is really information? Is the buried fossil of a yet to be discovered species of dinosaur information or not? These structures are not correlating with anything else we know of. Is it useful, then, to call them potential information? Information that is not (yet) about something is so because it has not yet been ‘read’. It seems quite intuitive that this potential information does not become actual information until it is read and once this happens, we know it shares mutual information with something else. The fact that it is a pattern with autocorrelation means that it does have the potential to become information in the relational sense, given the right context. It is however internally informational because of its autocorrelation and therefore we term it autonomous information.
Information as an Active Phenomenon
In “Information, Mechanism and Meaning”, DM MacKay referred to information as “a distinction that makes a difference’, this phrase later being popularised as a “difference that makes a difference” by Gregory Bateson. In this we again see reference to information as a relational property of patterns in matter, but this time it implies that there must be a consequence to the relationship. Information can only be defined when at least two patterns interact and can only be recognised by the consequence of the interaction. The sign of any such interaction having occurred is still, though, correlation among the patterns. The reason for this is that it would be impossible to tell if pattern A had affected pattern B unless A left a sign of its effect in B and the only sign that could be attributed to A is one which correlates with A. By ‘effect’ we mean that some information causes a change in some other information by interacting with it. If information produces this effect, we may call it effective information.
It could be argued that mutual information is neither necessary nor sufficient to establish effect. Just because one information pattern is correlated with another does not necessarily imply that it has any effect on it. For example, I share very many genes in common with my neighbour’s pet cat, so our DNA (as a whole) is highly correlated, but that in no way implies that my DNA is effecting that of the cat or vice versa. On the other hand, one pattern may have an effect on another without being (much) correlated with it. We know that enzymes have a great deal of effect if they are good ones, but their correlation with their target molecule can be very small (typically just a few atoms out of thousands, in what biochemists call the active site). Conversely, two protein molecules may be very similar, so share a high mutual information, but have little or no effect on one another. Unfortunately then, we cannot deduce the effectiveness of a biological molecule from the mutual information it shares with any other. Obviously what is missing is a causal explanation for the correlation found. For information to be effective, one pattern has to have caused a change in some other pattern, resulting in the appearance of mutual information among them. Finding this mutual information alone is a necessary, but by no means sufficient reason to claim that effective information has been found.
In the special case of nucleotides, we already know that they operate as templates for other molecules and with this, we can we deduce something about the effectiveness of the mutual information found between a nucleotide and some other molecule. Once we know the mutual information they share with a messenger or a protein molecule, we can say that they carried the information to make it. Whilst in general, mutual information appears to be a poor guide to effectiveness, if we can narrow the quantification to focus on only the effective part of a molecule, then mutual information would indeed be a good measure of effectiveness, but to do that, we need to already know the effect. An enzyme that perfectly matches its target in the region of activity will be maximally effective. It does so in only a small part of its molecular structure and here the mutual information with the target is enormous. For example A may be an enzyme which cleaves molecule B in two. Close inspection of this process reveals that the only way A can cleave B is if some (active) part of A chemically matches B at the cleaving site, i.e. some part of A must correlate with some part of B and where they do correlate, an effect may be had. In this way, mutual information turns out not only to quantify effectiveness, but to identify the part of a molecule (and more generally, of a system) that is effective in relation to another system or structure. (and here it is worth mentioning Schneider’s work again).
All this shows that non-zero mutual information is a necessary, but not a sufficient condition for effective information: recall the possibility of potential information which has yet to create any effect. We can easily answer that by describing potential effective information as any pattern that could cause a change in any other, once they met, but given the patterns before any interaction, we could not know whether or not an effect would result from their interaction.
When pieces of information combine to gain greater effect than their separate parts, the additional effect is a phenomenon of the complex created by them all in interaction with one another. The effect at this level of complex - a higher ontological level than that of the component parts - we refer to as ‘function’.
When A is combined with B, it creates C. Here C is the complex of which the function is a property. The functional information which arrises, embodied in C is additional effective information to that of A and B and appears only when they are in the correct relationship.
Function cannot appear out of nothing, it is the result of combining sets of effective information in a particular way and that particular way is itself embodied pattern, and so informational. When two pieces of information combine, information is instantiated in the particular relationship or configuration that is formed by the combination.